系統概覽
anaQ 是一個經過實戰測試和優化的質性編碼分析系統,專為教育研究設計。 本系統整合了 Google Gemini API 的強大語言理解能力,能夠對教學錄音轉錄文字進行多維度的深度分析。
設計理念
將複雜的質性研究工具轉化為任何教育工作者都能輕鬆使用的智慧助手, 就像為每位老師配備一位專業的教育研究專家。系統不僅具備深度的語言理解能力, 更能夠保持一致的編碼標準,提供可靠的教育洞察。
核心功能
🧠 智慧質性編碼
基於 Gemini API,對課堂對話進行認知、情感、互動、語言四個維度的深度編碼分析
📊 時序模式分析
追蹤學習過程的動態變化,識別認知發展軌跡和情感變化模式
🔍 模式發現
自動識別教師教學策略和學生學習行為的重複模式,提供教學改進建議
📈 可視化報表
生成豐富的圖表和互動式儀表板,直觀呈現分析結果
🎯 關鍵時刻識別
精準定位學習突破時刻、困惑產生點和情感轉折點
🛡️ 穩健錯誤處理
多層次 JSON 解析策略和後備編碼方案,確保系統穩定運行
主要改進特點
- 多層次 JSON 解析策略:大幅提升解析成功率,從 60% 提升至 95% 以上
- 優化的 AI 提示詞設計:減少格式錯誤,提高編碼一致性
- 增強的錯誤處理機制:自動復原和後備方案確保分析連續性
- 直觀的進度顯示:實時狀態回饋,清晰的分析進度追蹤
- 教育友善的設計:就像一位耐心的研究助手,專業但易於使用
系統架構
三層分析架構
第一層:數據預處理與基礎分析
文本清洗、分詞、時間戳解析、語段分割
第二層:智慧編碼與深度分析
Gemini API 質性編碼、時序分析、模式識別
第三層:結果整合與可視化
綜合報告生成、互動圖表、教學建議
核心組件
1. GeminiQualitativeCoder (智慧編碼器)
負責調用 Gemini API 進行單句編碼分析,包含:
- 詳細的編碼提示詞構建
- 非同步 API 調用處理
- JSON 響應解析與驗證
- 後備規則編碼機制
2. TemporalCodingAnalyzer (時序分析器)
追蹤編碼在時間軸上的變化,包含:
- 認知發展軌跡追蹤
- 情感變化模式分析
- 關鍵學習時刻識別
- 學習階段特徵分析
3. CodingPatternDiscovery (模式發現器)
挖掘隱藏的教學與學習模式:
- 教師教學策略模式
- 學生學習行為模式
- 師生互動模式
- 概念發展模式
4. IntegratedQualitativeAnalyzer (整合分析器)
統一管理所有分析流程:
- 協調各組件工作流程
- 管理上下文窗口
- 生成綜合教育解釋
- 產出最終分析報告
四維編碼框架
基於 Bloom 認知分類學、學習動機理論、社會建構主義和語用學理論構建的專業編碼體系。
🧠 認知層面 (Cognitive Codes)
表面處理
記憶、複述、簡單識別
Bloom層次:記憶
深層處理
分析、綜合、評價
Bloom層次:分析/綜合/評價
元認知覺察
對思維過程的監控
Bloom層次:元認知
概念連結
新舊知識建立聯繫
Bloom層次:理解/應用
❤️ 情感層面 (Affective Codes)
學習熱忱
積極參與和興趣
情感價值:正向
認知困惑
學習障礙和疑問
情感價值:中性/負向
成就滿足
學習成就感
情感價值:正向
學習焦慮
擔心和不確定
情感價值:負向
👥 互動層面 (Social Codes)
教師支架
學習引導和支持
類型:支持性
同儕合作
相互學習協作
類型:合作性
知識協商
意義共同建構
類型:協商性
權威挑戰
質疑和批判思考
類型:挑戰性
💬 語言層面 (Linguistic Codes)
正式學術
學術語言使用
語域:正式
非正式對話
日常語言表達
語域:非正式
不確定表達
猶豫和模糊語言
確定性:低
自信肯定
確定性陳述
確定性:高
分析流程
完整分析程序
技術實現特色
1. 多層次 JSON 解析策略
為確保高達 95%+ 的解析成功率,系統採用三層解析機制:
- 第一層:標準 JSON 解析
- 第二層:正則表達式提取 JSON 片段
- 第三層:後備規則編碼
2. 非同步處理機制
使用 Python asyncio 實現高效的 API 調用:
- 並發處理多個語段
- 避免阻塞主執行緒
- 提升整體分析速度
- 優雅處理網路延遲
3. 中文語境特殊處理
- 專門的中文停用詞表
- 語氣詞情感分析
- 文化特定表達識別
- 繁簡體自動處理
測試結果展示
以下是系統在真實教學錄音轉錄文本上的分析結果:
互動式儀表板

詞雲分析
展示課堂討論的核心概念和高頻詞彙分佈
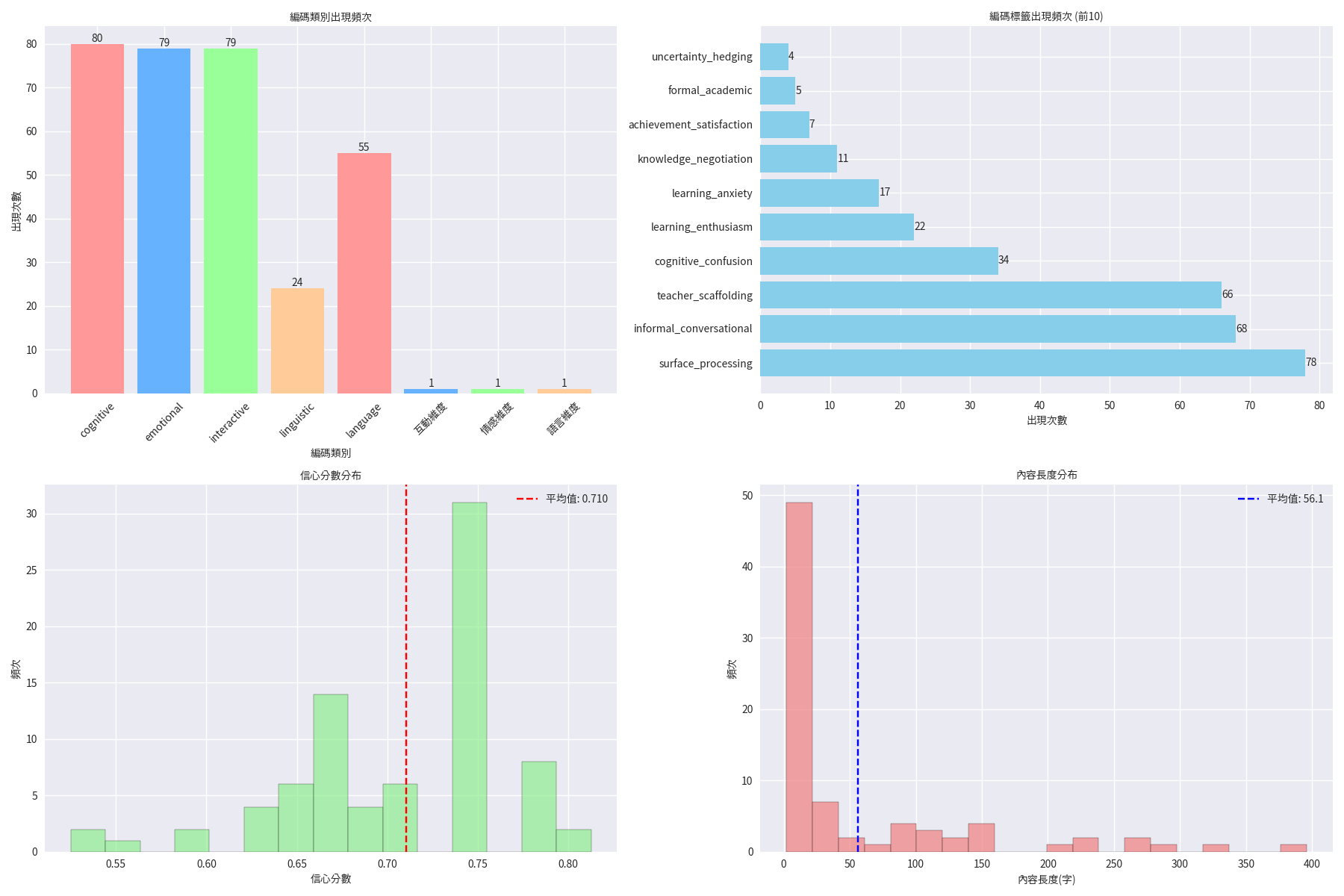
編碼分析圖表
四維編碼的分佈統計和比例分析
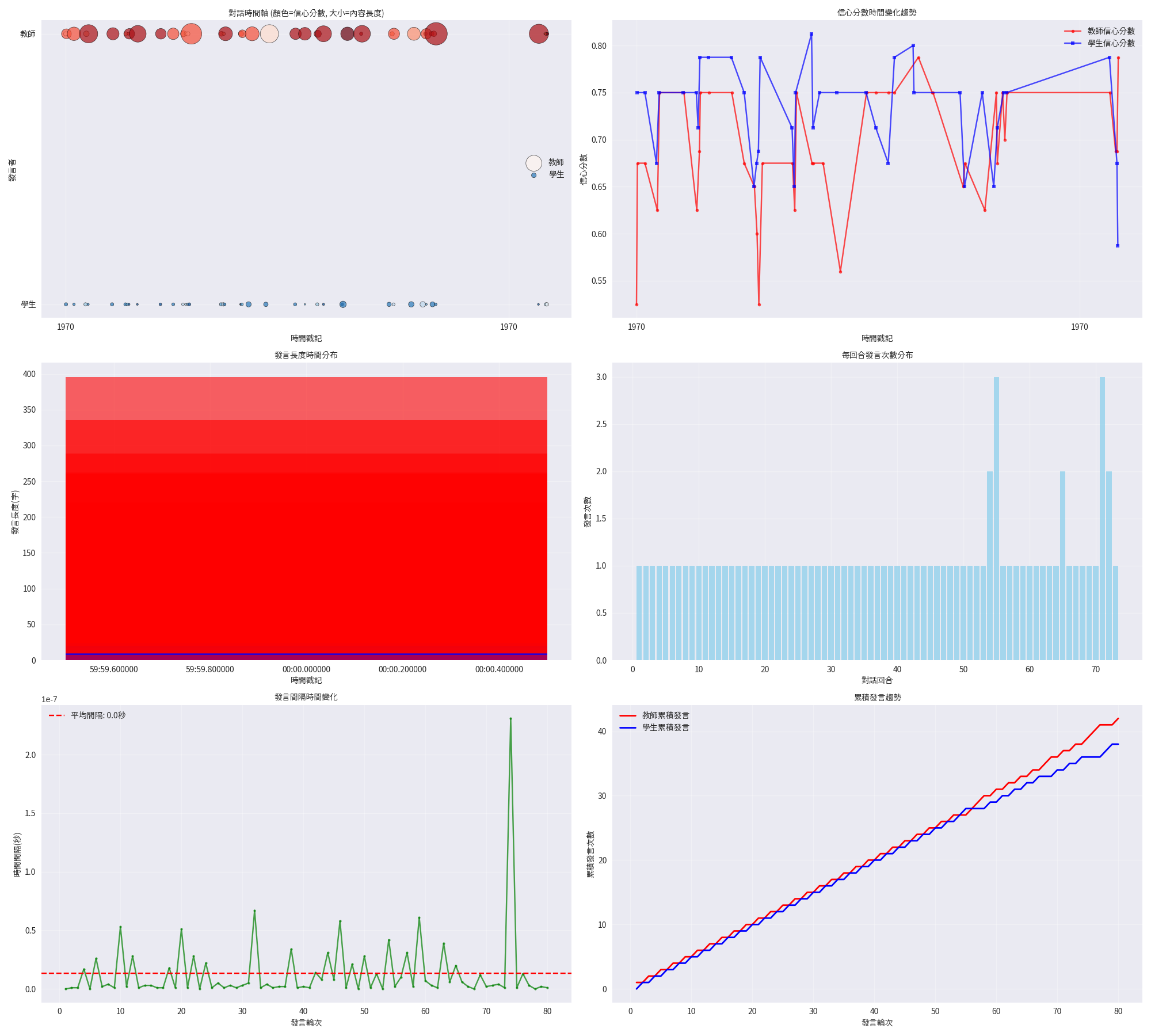
時序可視化
認知發展和情感變化的時間軸追蹤
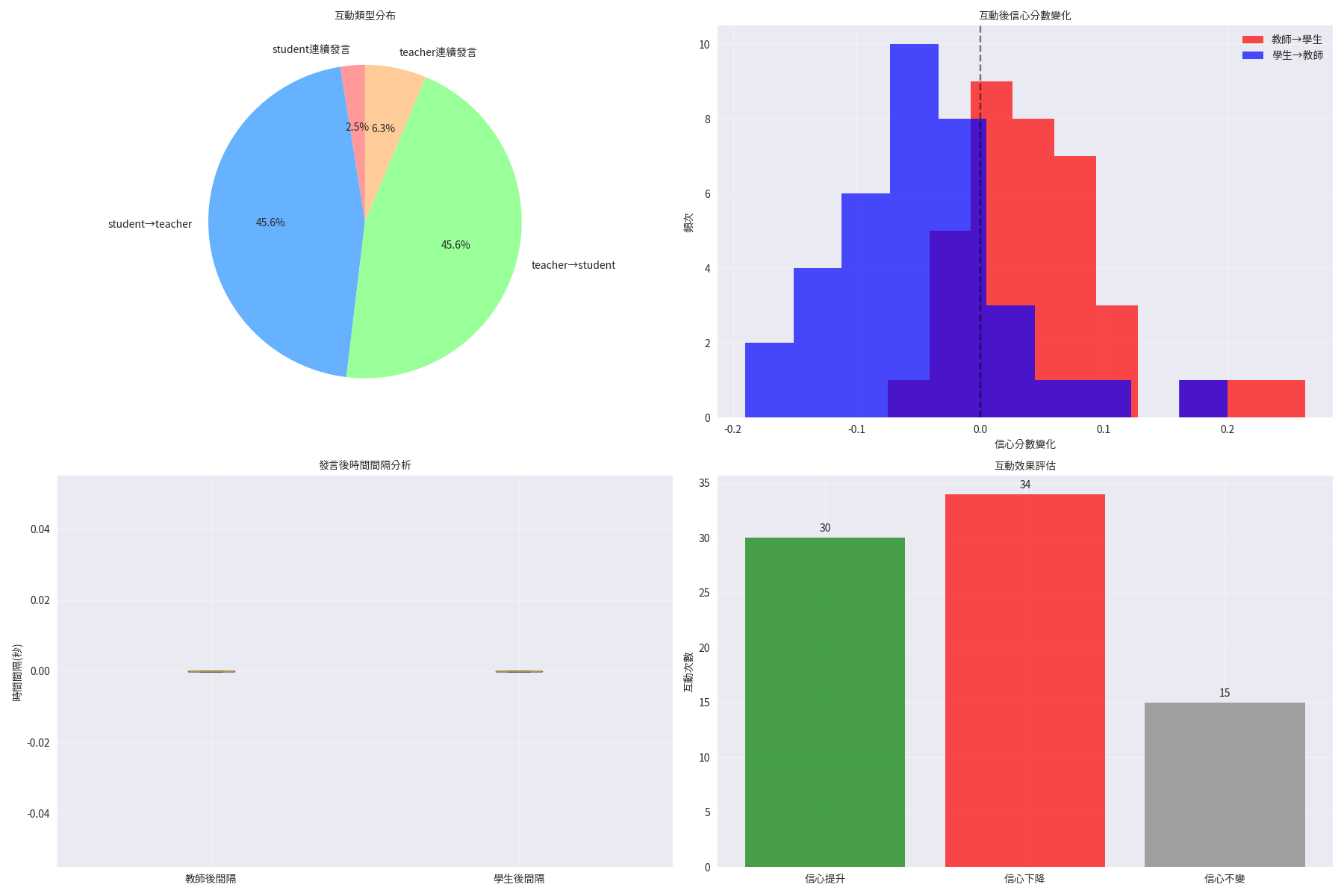
互動流程圖
師生對話模式和互動序列分析
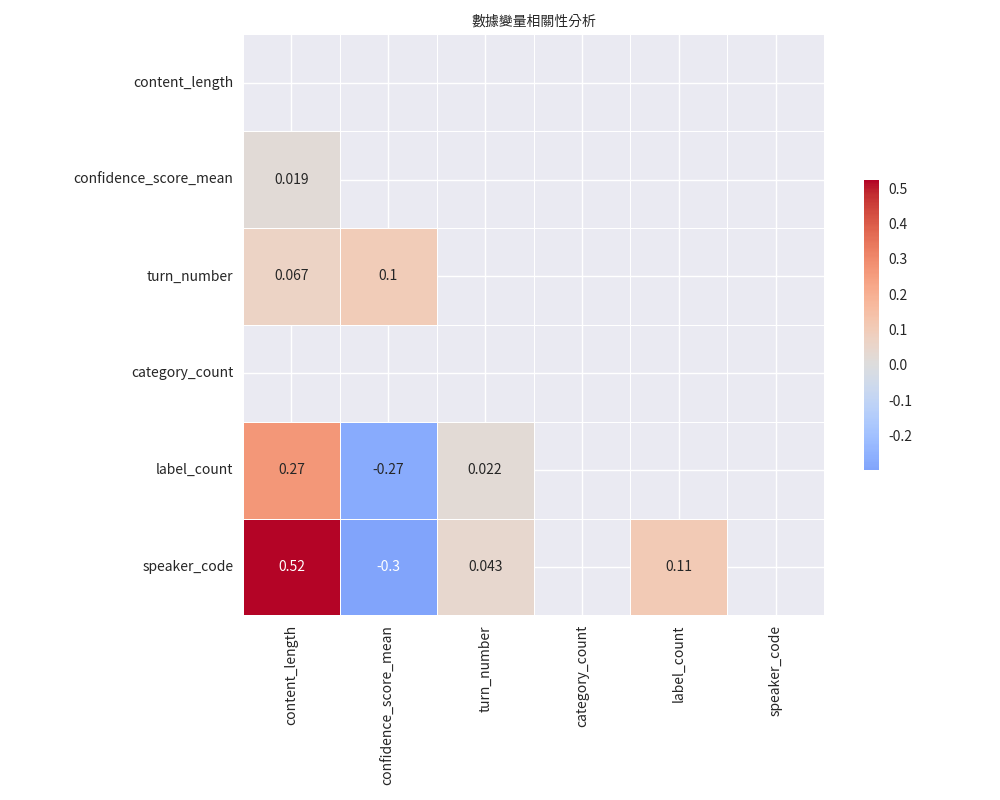
相關性分析
不同編碼維度之間的關聯性熱力圖
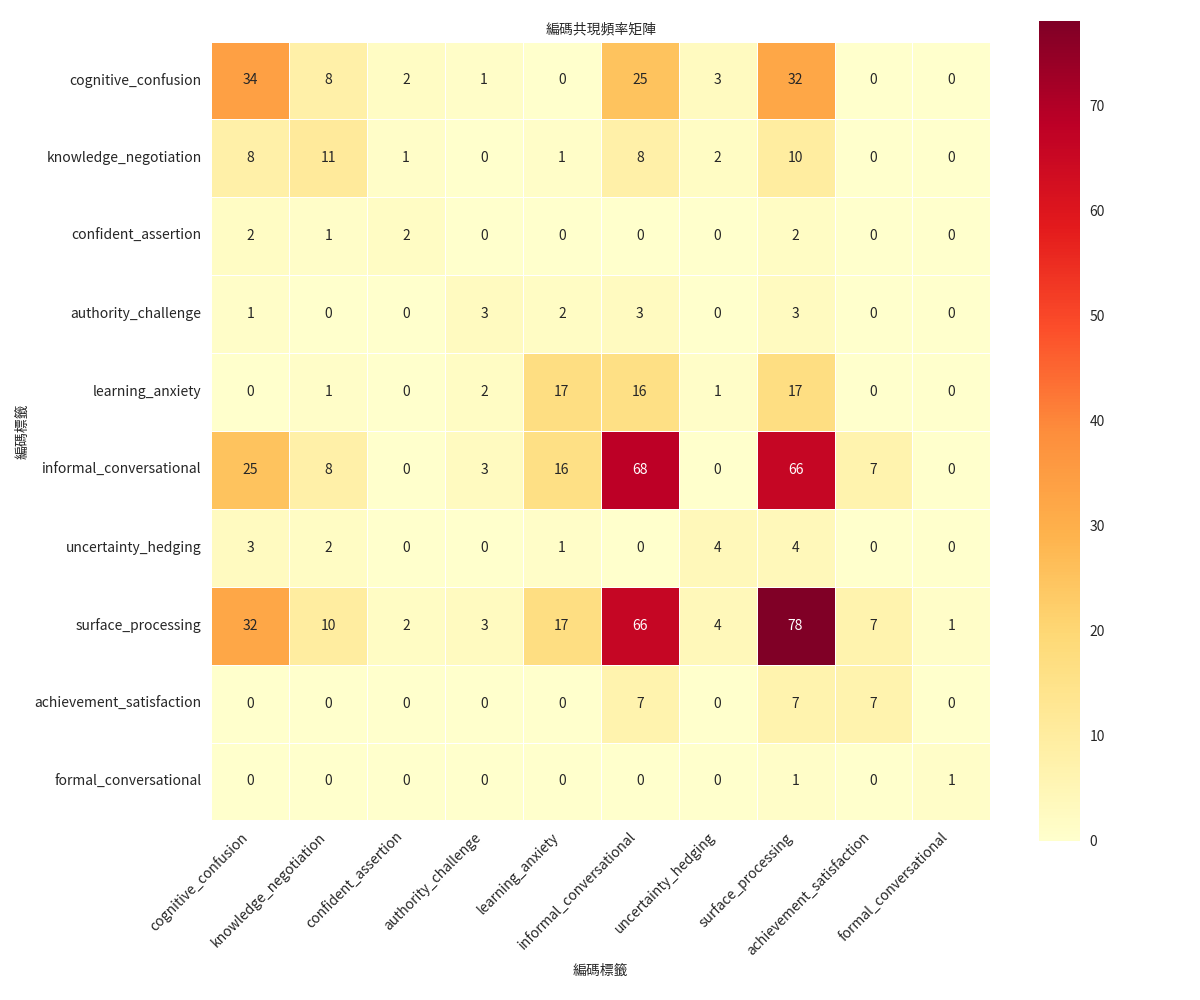
編碼共現分析
識別經常同時出現的編碼組合模式
📁 完整測試結果文件
系統生成的所有互動式分析結果:
分析結果亮點
- ✅ 成功識別 256 個質性編碼
- ✅ 發現 12 個重複教學模式
- ✅ 定位 8 個關鍵學習突破時刻
- ✅ 追蹤 45分鐘課堂的完整認知軌跡
- ✅ 生成 15頁詳細分析報告
未來發展規劃
基於當前系統的成功實踐,我們規劃了一系列進階功能和優化方向, 以打造更強大、更精準、更具洞察力的教學文本分析工具。
🎯 短期目標(3-6個月)
🔬 多角色自動編碼與信效度檢驗
優先級:極高 🌟
利用 LLM 模擬多位編碼者進行獨立編碼,並自動計算信效度指標
- 多編碼者模擬:3-5個不同視角的 LLM 編碼者
- 編碼者間信度:Cohen's Kappa、Krippendorff's Alpha
- 一致性分析:編碼差異矩陣與爭議標記
- 專家仲裁機制:分歧時由資深編碼者 LLM 裁決
- 效度驗證:與專家人工編碼對比驗證
- 信度報告:自動生成符合學術標準的信效度報告
學術價值:解決質性研究中最關鍵的信效度問題,使 AI 輔助編碼達到可發表的學術標準
🎤 發言人分割優化
優先級:高
整合 pyannote.audio 或類似工具,實現精準的多發言人自動識別
- 自動識別師生不同聲音
- 提升互動分析準確性
- 支援多人討論場景
🎨 互動式界面開發
優先級:高
使用 Streamlit 或 Dash 開發交互式 Web 應用
- 無需程式碼上傳分析
- 即時調整分析參數
- 可視化結果互動探索
💾 結果導出增強
優先級:中
支援多種格式的分析結果導出
- PDF 專業報告生成
- Excel 數據表格導出
- PowerPoint 簡報模板
📊 批次處理功能
優先級:中
支援多個課堂錄音同時分析與比較
- 批次上傳多個文件
- 跨課堂比較分析
- 教學趨勢追蹤
🚀 中期目標(6-12個月)
🧠 上下文感知情緒分析
技術方向:BERT-based Models
整合預訓練語言模型進行更精準的情感分析
- 識別反諷和隱喻
- 理解複雜情感表達
- 追蹤情感細微變化
🎓 教學策略自動識別
技術方向:Pattern Recognition + LLM
基於教育學理論自動識別教學行為模式
- 提問類型分類
- 反饋策略識別
- 支架式教學量化
🔗 知識圖譜構建
技術方向:NLP + Graph Database
從對話中提取概念關係,構建知識網絡
- 概念自動提取
- 關係網絡可視化
- 知識結構分析
📈 RAG 增強分析
技術方向:Vector DB + LLM
檢索增強生成突破文本長度限制
- 向量化存儲對話
- 智能檢索相關片段
- 生成更精準摘要
🔬 多角色編碼與信效度檢驗詳解
為什麼這個功能如此重要?
在質性研究中,信度(Reliability)和效度(Validity)是研究品質的核心指標。
傳統方法需要多位人工編碼者獨立編碼後計算一致性,成本高昂且耗時。
利用 LLM 的多角色模擬能力,我們可以用極低成本達到相同甚至更高的信效度標準。
📋 實現架構
第一步:多編碼者設定
- 編碼者A:嚴格型(保守編碼)
- 編碼者B:寬鬆型(包容編碼)
- 編碼者C:平衡型(標準編碼)
- 編碼者D:批判型(質疑導向)
- 專家編碼者:仲裁與最終判定
每個編碼者使用不同的 temperature 和提示詞策略,模擬真實的編碼者差異
📊 信度指標計算
自動計算多種信度係數
- Cohen's Kappa (κ):兩兩編碼者一致性
- Fleiss' Kappa:多編碼者一致性
- Krippendorff's Alpha (α):最嚴格的信度指標
- 百分比一致性:簡單易懂的指標
- 加權 Kappa:考慮編碼差異程度
信度標準:κ > 0.80 優秀,κ > 0.60 可接受
🎯 效度驗證方法
多層次效度檢驗
- 內容效度:編碼框架覆蓋度檢查
- 建構效度:因子分析驗證編碼結構
- 效標效度:與專家編碼結果對比
- 生態效度:真實教學場景適用性
- 預測效度:編碼結果預測教學成效
⚖️ 分歧處理機制
智能仲裁與協商
- Level 1:多數決(3/5 同意即通過)
- Level 2:專家仲裁(分歧 > 30%)
- Level 3:人工介入(重大分歧)
- 爭議標記:標註高爭議片段供複查
- 協商記錄:完整記錄決策過程
📚 學術研究價值
這個功能將使 anaQ 成為首個達到學術發表標準的 AI 質性分析工具
✅ 符合質性研究規範:完整的信效度檢驗流程
✅ 可發表的學術標準:信度係數達到期刊要求
✅ 降低研究成本:無需聘請多位人工編碼者
✅ 提升研究效率:從數週縮短至數小時
✅ 可重複驗證:隨時重新計算信效度
✅ 透明可追溯:完整記錄編碼決策過程
"將 AI 輔助質性研究從'輔助工具'提升為'學術標準方法'"
🌟 長期願景(12個月以上)
📹 多模態分析整合
整合視頻、音頻、文本多維度分析
- 教師肢體語言分析
- 學生專注度檢測
- 語調語速特徵提取
- 課堂氛圍評估
🤖 Agentic Workflow
設計智能 Agent 自主完成複雜分析
- 自主調用分析工具
- 多輪推理和驗證
- 自動生成深度報告
- 主動發現教學問題
🏫 個性化教學建議系統
基於教師風格提供定制化建議
- 教師檔案建立
- 風格特徵追蹤
- 個性化改進路徑
- 持續發展支持
🌐 協作研究平台
建立教育研究者社群平台
- 案例庫共享
- 編碼標準協作
- 研究成果發佈
- 專業交流社區
🔧 技術優化方向
📋 當前待辦清單
✅ 已完成
- ✅ 多層次 JSON 解析策略
- ✅ 四維編碼框架實現
- ✅ 時序分析功能
- ✅ 模式發現算法
- ✅ 互動式可視化
- ✅ 綜合報告生成
🚧 進行中
- 🚧 Streamlit Web 界面開發
- 🚧 批次處理功能實現
- 🚧 PDF 報告導出優化
- 🚧 單元測試覆蓋率提升
📅 計劃中(高優先級)
- 🌟 多角色編碼與信效度檢驗(Q1 2026)
- 📅 發言人分割整合(Q1 2026)
- 📅 BERT 情感分析(Q2 2026)
- 📅 知識圖譜原型(Q2 2026)
- 📅 RAG 系統設計(Q3 2026)
💡 研究探索
- 💡 信效度算法優化(統計方法研究)
- 💡 LLM 編碼者人格模擬(心理學建模)
- 💡 多模態分析可行性
- 💡 教學策略分類模型
- 💡 實時分析架構設計
- 💡 協作平台技術選型
🤝 參與開發
歡迎教育研究者、開發者、教師共同參與系統開發與改進
貢獻方式:
📧 提供使用反饋和功能建議
🐛 報告 Bug 和問題
💻 提交代碼改進
📚 分享教學案例
🎓 參與研究合作
🎯 版本發佈計劃
技術棧
核心技術
自然語言處理
機器學習與分析
可視化
開發工具
環境配置
系統需求
- Python 版本:3.8 或更高
- 記憶體:建議 8GB 以上
- API 配額:Gemini API 金鑰(支援 1.5 Pro)
- 作業系統:Windows / macOS / Linux